
Articul8 Elevates Its Finance GenAI Stack with a Table Understanding Agent and Enhanced A8-FinDSM, Delivering Deep Financial Document Intelligence
Now Available on AWS Marketplace, the Table Understanding Agent instantly transforms dense financial PDFs, statements, and regulatory filings into structured, model-ready data, removing the biggest bottleneck blocking GenAI adoption in financial services
In the high-stakes arena of financial services, data powers every decision, from trades to risk models to client interactions. But decisions made on faulty assumptions can erase investor returns, while compliance failures can trigger billions in fines, not to mention reputational damage. Additionally, accuracy only matters when it gets delivered quickly. Despite having oceans of information, most institutions remain stuck at the surface. Siloed, unstructured data leaves its full value locked away, forcing staff to painstakingly comb through disparate sources while compliance teams navigate regulatory mazes. The result? An industry that depends on speed and precision is slowed to a crawl with manual document review of burdening analysts.
This challenge for B2B financial services firms demands more than broad-based AI. While general-purpose LLMs impress with range, financial services require something different: precision, trust, and deep domain expertise. The real breakthroughs emerge when models are trained in the language of finance, where nuance, compliance, and context aren't optional features but essential requirements. Information that now takes weeks for an analyst to review can be done so in seconds. The data that powers these models needs to be extracted quickly and autonomously with the help of agentic AI.
The News: Introducing the Table Understanding Agent that’s Purpose-Built to Unlock Financial Data at Scale
While domain-specific models outperform general-purpose LLMs on financial reasoning, compliance interpretation, and credit or risk evaluation, financial institutions have continued to struggle with the step that comes before the analysis: capturing all of the underlying data through converting complex, irregularly formatted financial tables packed with multi-level headers, hierarchical groupings, and numeric fields intermixed with symbols into structured, trusted data that models can process reliably.
It’s a real problem, because traditional OCR and RAG pipelines capture only 30–50% of the information in complex financial tables. Headers collapse, values misalign, and key modifiers vanish, leaving tables that appear intact but are too structurally compromised to support sound financial analysis.
That changes today.
Articul8’s Table Understanding Agent, now available on AWS Marketplace, tackles this challenge head-on by treating financial tables as semantic objects rather than OCR fragments. Designed specifically for the irregular, high-density structures found in financial statements, regulatory filings, ESG reports, loan books, and portfolio disclosures, the agent performs real-time multimodal reconstruction that delivers clean, structured, model-ready data for downstream analytics and reasoning agents.
Instead of analysts spending days reviewing PDFs and spreadsheets, the agent parses complex layouts in seconds, detecting things like multi-level headers, merged cells and footnotes, cross-referenced units, embedded tables inside narrative text, numerical fields packed tightly with symbols, currencies, and dimension changes. Articul8’s multi-modal system captures as much as 20 times more details because it understands how a table is structured and how numbers and labels inter-relate. That structural and semantic fidelity prevents the small omissions that lead to big analytical misses, giving financial institutions the clarity required for high-stakes decision-making.
The result is trusted, structured financial data delivered instantly. Each table is streamed via SSE with full metadata, and the final event returns a Base64-encoded ZIP containing one CSV per table, ready for ingestion into downstream AI workflows. The result is clean, structured, model-ready data, instantly. With a simple usage-based pricing model where customers pay only for successfully extracted tables, enterprises eliminate both the operational burden and the cost inefficiencies of legacy OCR or rules-based document systems.
The Table Understanding Agent requires no template setup, no pre-processing rules, and no manual correction loops. It adapts automatically to new financial document formats, scales across batch workloads, and integrates seamlessly into existing data and GenAI environments. Financial teams can deploy in hours, not months, with measurable productivity gains from day one.
And when paired with A8-FinDSM, data capture becomes insight generation, enabling autonomous interpretation, benchmarking, and predictive reasoning rooted in financial expertise. Together, they form a unified Finance GenAI stack that finally bridges the gap between unstructured financial documents and enterprise-grade financial decision-making.
How the Table Understanding Agent Works
The Table Understanding Agent integrates multimodal document perception with GenAI-powered table reasoning to accurately reconstruct complex financial tables through a five-stage interpretation pipeline. Each table is streamed in real time as structured JSON with page metadata, and a Base64-encoded ZIP of CSV files is delivered upon completion. Traditional OCRs treat documents as plain text. They capture characters but do not understand the relationship between elements, which causes LLMs to miss the meaning of the information. It analyzes PDFs, images, and scans to identify table regions, structural markers, and header hierarchies, even when embedded within narrative text. Advanced vision-language models reconstruct multi-level headers, merged cells, nested structures, currency units, and numerical formatting with precision, while semantic normalization processes footnotes, annotations, and contextual modifiers such as "in millions" or "constant currency." By unifying multimodal perception, structural reconstruction, and real-time delivery, the agent transforms unstructured financial documents into trustworthy, model-ready data for A8-FinDSM, forecasting models, anomaly detection agents, and BI pipelines at enterprise scale. Beyond financial services, the agent brings the same level of precision to other data-intense industries. It can accurately parse multi-header engineering specifications, navigate multi-page and multi-condition energy-utility documentation, and extract hierarchical data from telecom inventories. Where documents lack neat rows and columns with nested headers, this agent outshines the competition.
Despite the identical formatting and close proximity, the Table Understanding Agent correctly isolated each table and reconstructed them with full row, column, and value fidelity.
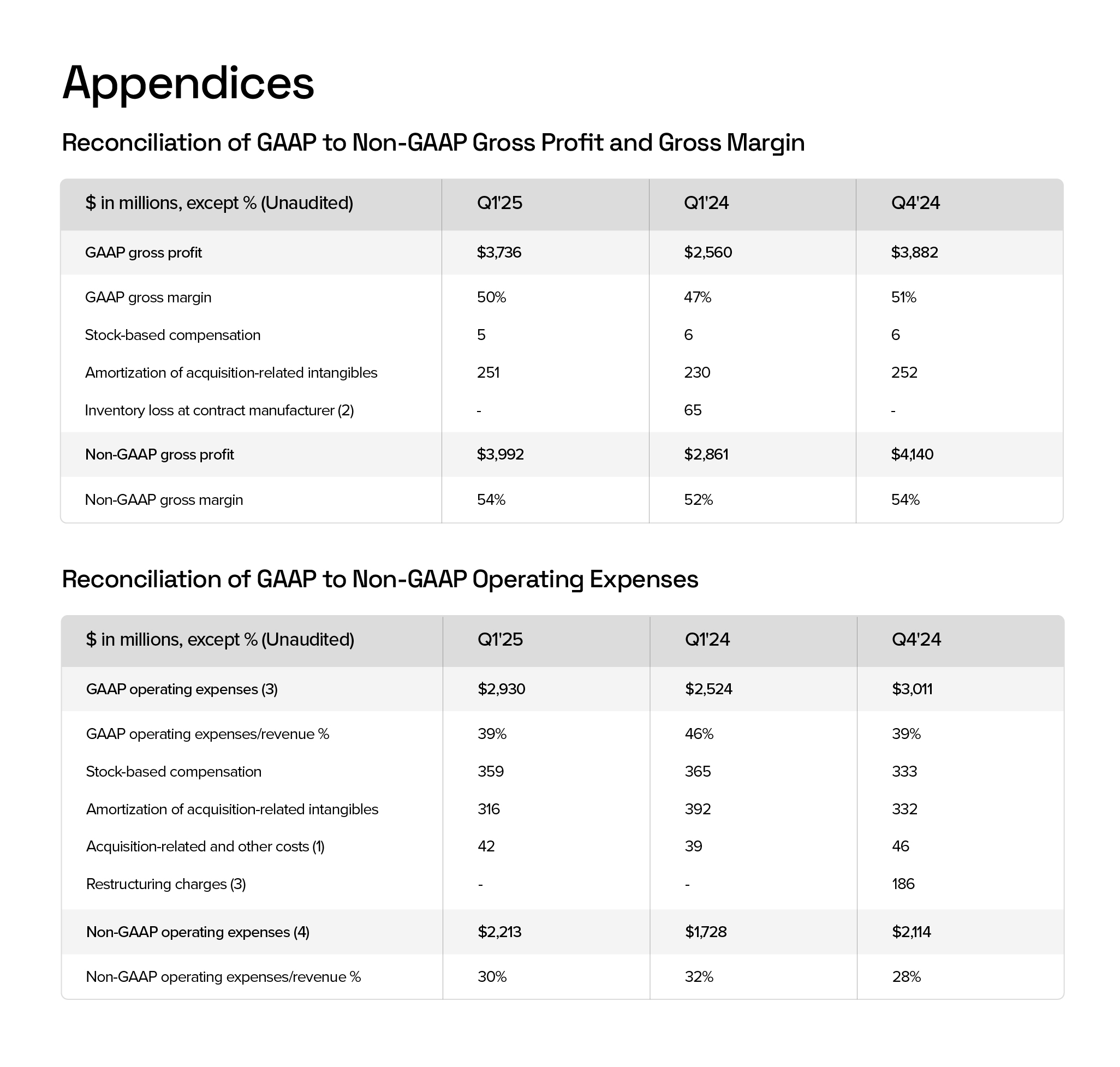
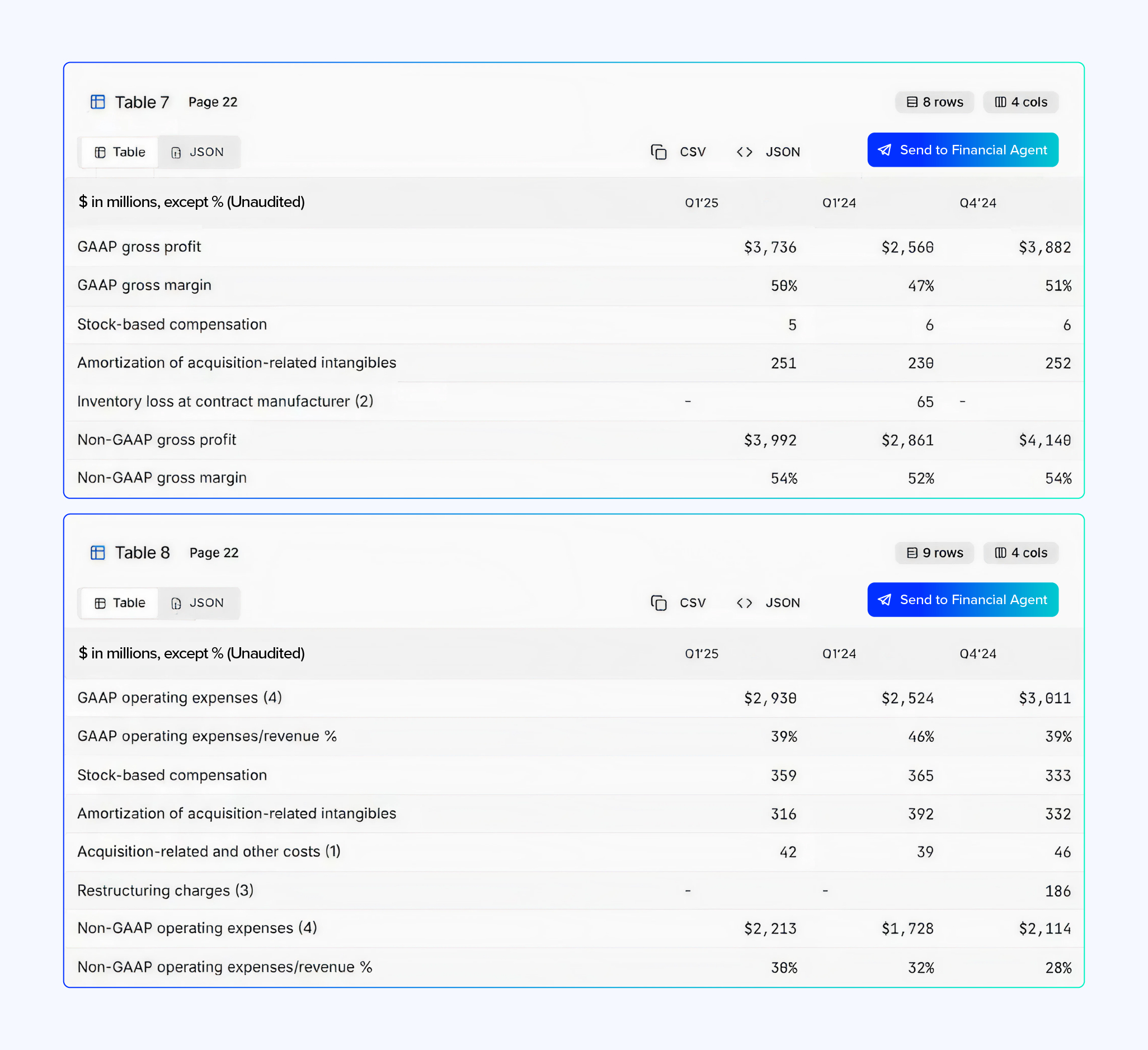
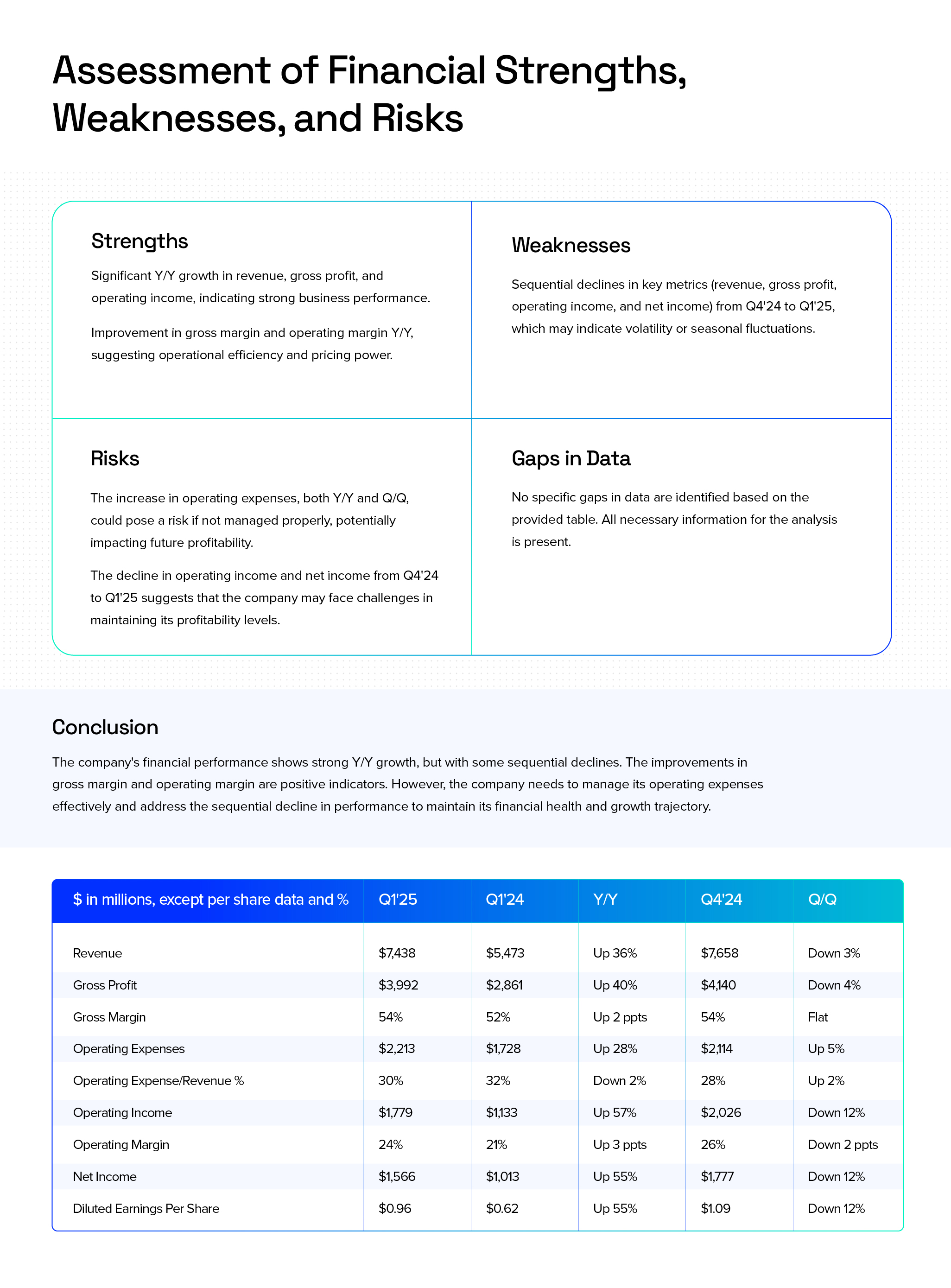
Once the tables are processed, our domain-specific model interprets the metrics and produces strengths, weaknesses, risks, and a full financial assessment.
See how our agent works in the video below
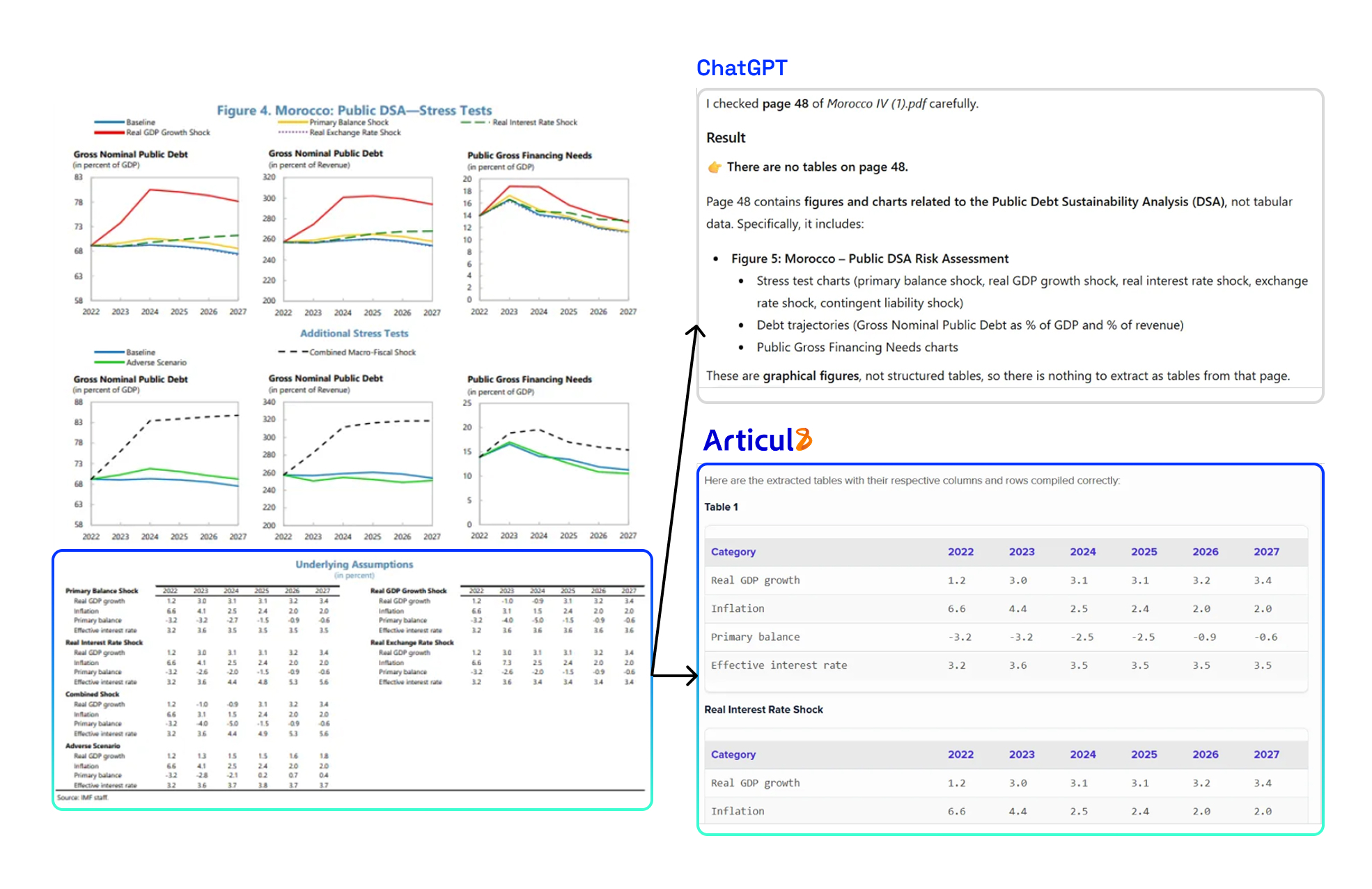
The example below shows a page filled with charts, with tables tucked away and less prominent. Models like ChatGPT and Claude missed these tables entirely, focusing instead on the visual charts.
The Articul8 Table Understanding Agent found and extracted the tables anyway, correctly identifying their boundaries, preserving headers, and keeping the data aligned. This highlights a key difference: while other models rely on what stands out visually, Articul8 understands structure, allowing it to accurately capture tables even when they’re subtle, embedded, or surrounded by complex graphics.
Industry Examples Capturing Analyses Beyond Finance
These challenges with reading tables and interpreting data extend beyond financial reports. And financial analysts need context from industry data as well. Nearly every industry relies on tables to house critical information, often with a mix of structured and unstructured formats, with complex layouts, layered headers, conditional relationships and hierarchies. Documents across engineering, manufacturing and automotive encode meaning through structure, not just text. And like finance, precision matters. LLMs struggle with interpreting this data as well, as illustrated in the following examples.
Structural engineering
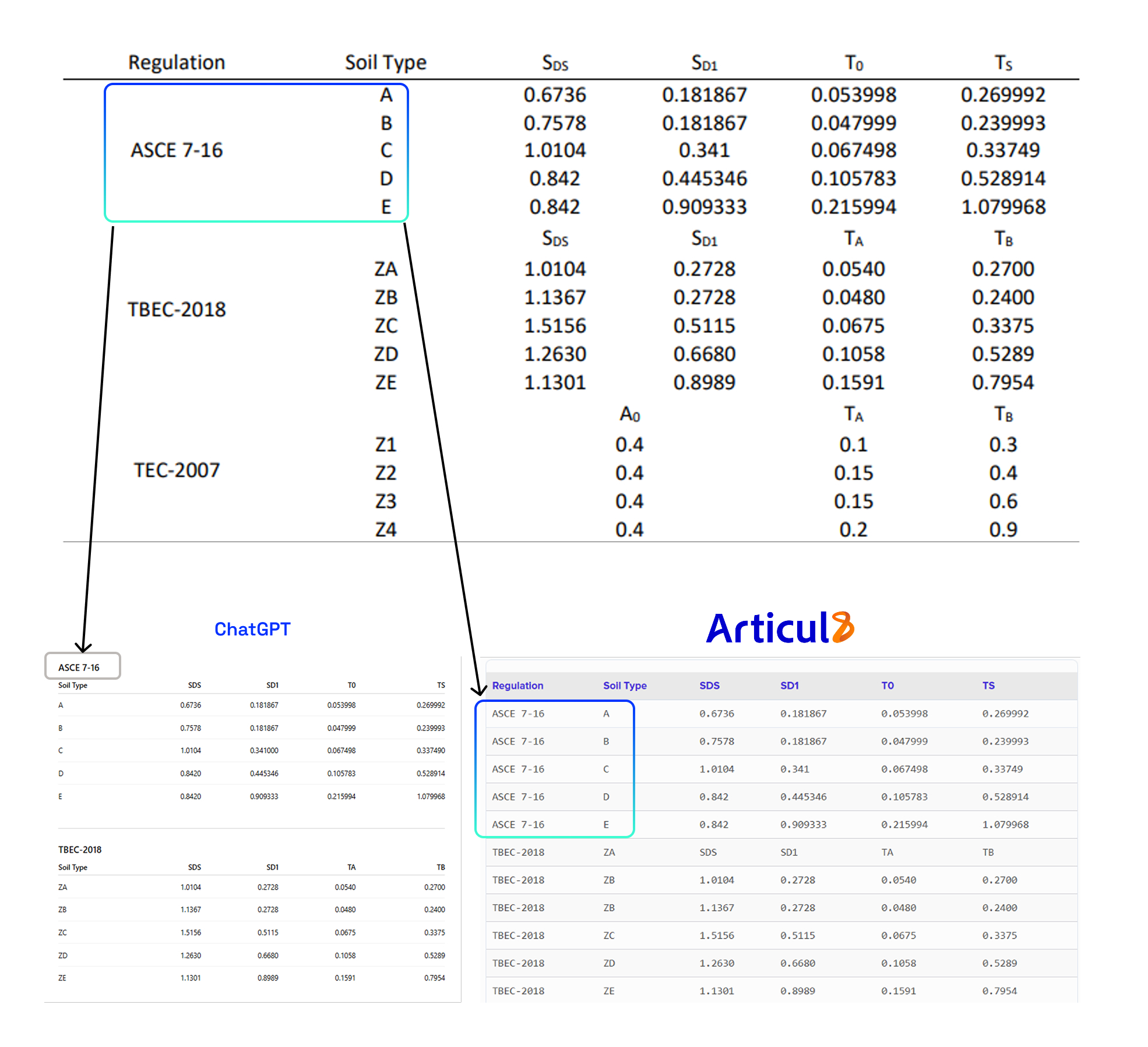
Engineering specification tables are difficult for AI because meaning is embedded in structure. General models misread these elements, reducing accuracy. In the table below, ChatGPT misclassified “ASCE” as a table title instead of a column header, breaking header-to-data relationships and reducing accuracy. This makes or breaks projects, as critical data on dimensional tolerances, environmental conditions and performance constraints carry safety implications. Articul8’s Table Understanding Agent preserves structural relationships, producing a usable, engineer-accurate representation for compliance and verification.
Automotive documentation
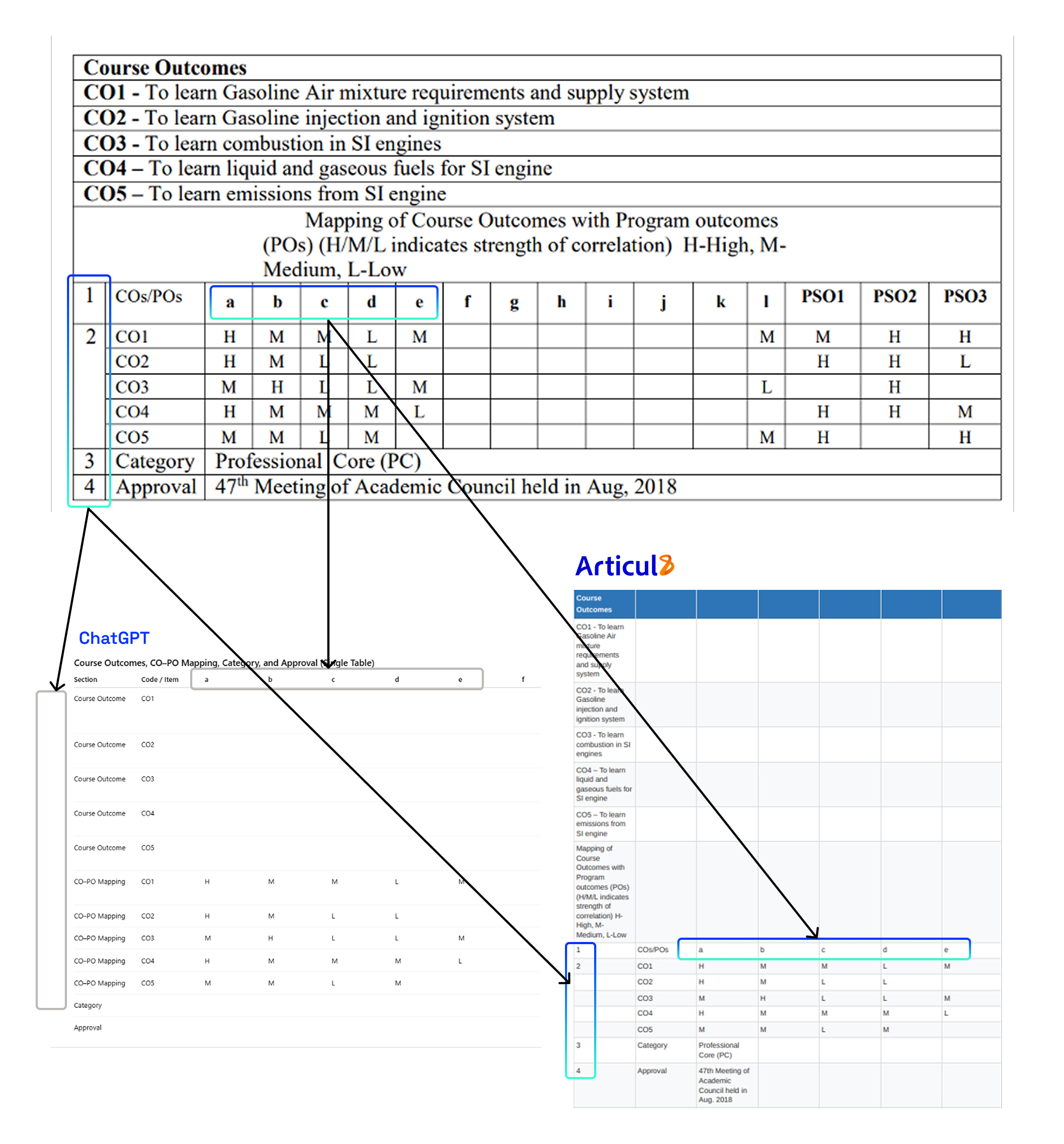
Vehicle specs, validation matrices and compliance tables rely on multi-level headers that apply only to specific conditions. This adds another layer of complexity that general LLMs struggle with. The chart below illustrates how Articul8’s Table Understanding Agent preserves these multi-level relationships, keeping each measurement tied to the correct vehicle configuration, while ChatGPT missed an entire set of columns and elevated sub-headers to the top level. Maintaining data accuracy enables automotive validation, compliance and quality workflows.
Why Finance Needs a Specialist
Imagine a financial analyst tasked with building an investment profile for an automotive manufacturer -- comparing revenue, R&D spend, and growth across US and Japanese competitors. This request sounds straightforward, but the work is anything but. It requires sifting through labyrinths of 10-K filings, parsing hours of earnings calls, and decoding sprawling spreadsheets. The answer doesn’t exist in any single document, and a search engine won’t cut it.
What’s required is reasoning across scattered data, guided by deep subject-matter expertise. Modern analysts don’t just need organized figures; they need predictive insight – delivered through Autonomous Data Perception, which gathers, interprets, and contextualizes information while anticipating intent. That’s where domain-specific models stand apart.
A general LLM offers a beginner's grasp, surfacing broad truths. A DSM, by contrast, delivers expert-level insight with strategic depth and regulatory context.
GenAI Built to “Speak Finance”
Articul8’s A8-FinDSM was created to meet the demand for expertise, and the Table Understanding Agent makes delivering value from data faster. While the Table Extraction Agent captures and extracts the data, the model interprets it and unlocks insights. Unlike general-purpose models trained on internet-scale data, A8-FinDSM is immersed in the specialized language of finance. Its training corpus includes millions of SEC filings, earnings call transcripts, FINRA filings, analyst reports, and decades of regulatory filings. These products work together as part of Articul8’s full Generative AI platform stack, powered by its ModelMesh orchestration plane which autonomously assembles the right models and agents for complex, domain-specific tasks.
The result is a model that doesn’t just parse numbers -- it understands the difference between GAAP and non-GAAP metrics, interprets nuanced language shifts in CEO commentary, and contextualizes R&D spend within competitive industry benchmarks. It speaks finance the way your analysts do.
The Performance Gap That Matters
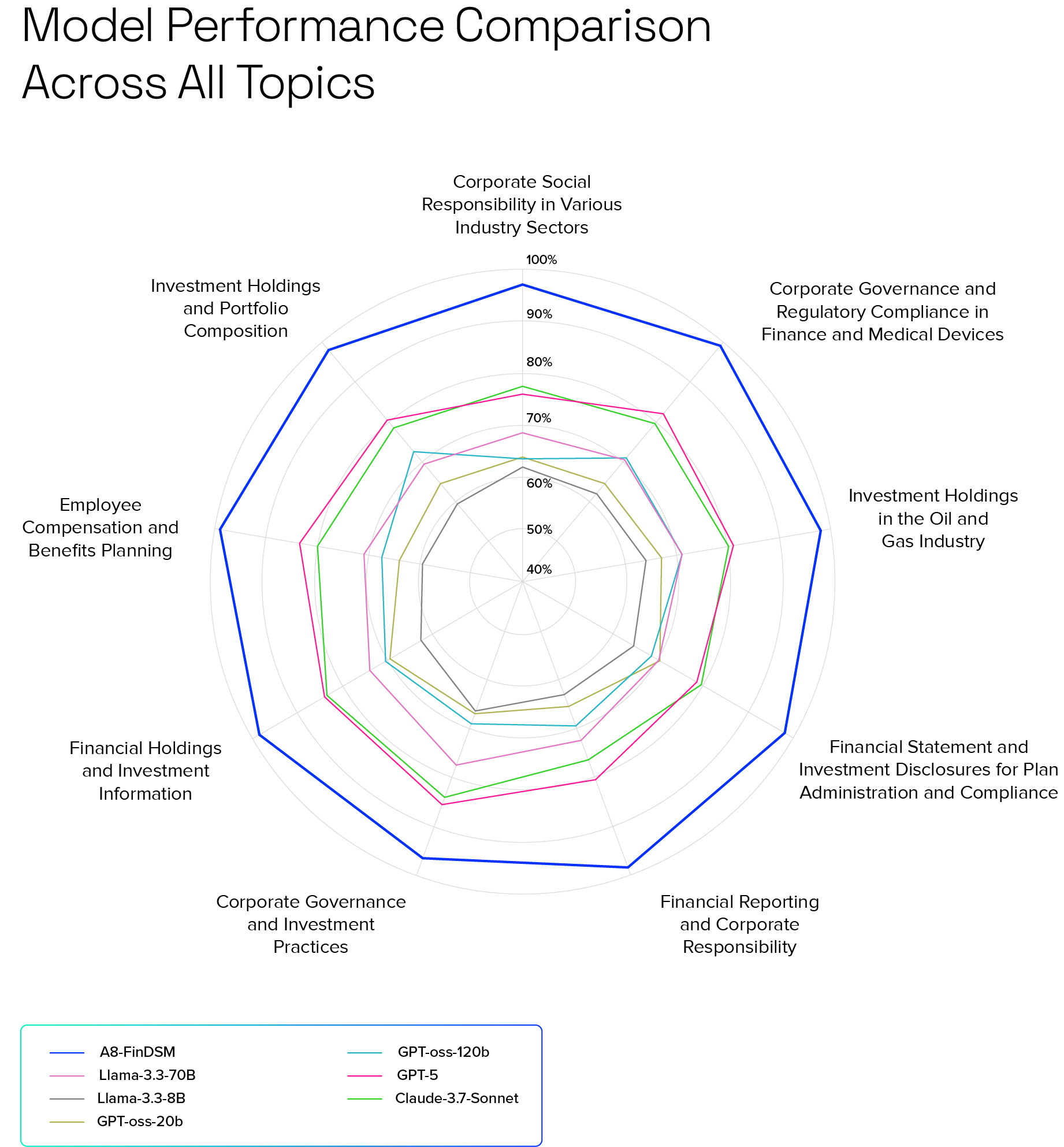
We tested the A8-FinDSM across critical financial services topics, from corporate governance and regulatory compliance to investment holdings, portfolio composition, and sector-specific insights like oil and gas, among others. And the results speak for themselves:
- Corporate governance and regulatory compliance: 99% accuracy (vs. 76% for GPT-5)
- Investment holdings: 98% accuracy (vs. 81% for GPT-5)
- Financial statement and investment disclosures: 98% accuracy (vs. 78% for GPT-5)
This level of accuracy empowers analysts to make smarter, faster investment decisions. With precise compliance and governance signals, firms can identify risks early and anticipate regulatory impacts on stock performance. Models can parse financial statements and disclosures with precision, enabling rapid trend analysis, ratio calculations, and forecasting. Investment holdings and portfolio insights give analysts a clear view of asset allocation, sector exposure, and diversification. All in a fraction of the time.
The performance difference, sometimes more than 20%, shifts the advantage from mere incremental improvement to a defining competitive edge. It means thousands of fewer hours spent chasing wrong leads, reduced exposure to compliance errors, and better reads on market sentiment, preventing costly missteps. A8-FinDSM also runs 3.5x more cost-efficient than even the best open-source LLMs. This performance advantage translates into operational costs saved and, more importantly, revenue gained because of greater confidence in decisions made under pressure and capitalizing on opportunities.
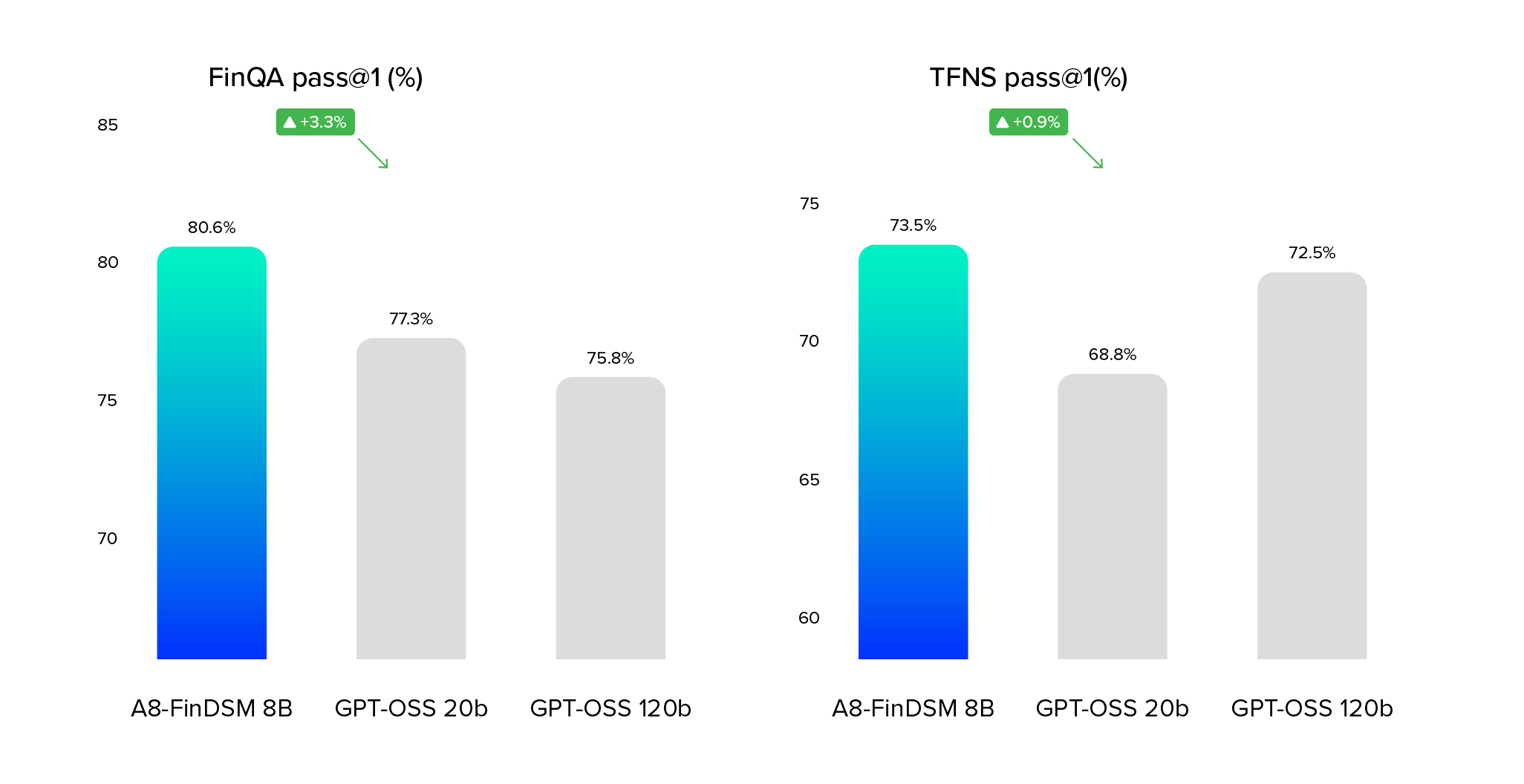
We also measured A8-FinDSM against academic benchmarks like FinQA and TFNS to evaluate its performance on financial reasoning and question answering. These datasets provide useful insights into technical capabilities, and focus primarily on research-focused metrics rather than business impact. Real-world performance depends on factors like workflow integration, data coverage, and actionable insights. Even so, A8-FinDSM outperforms leading models on these benchmarks, reinforcing its strong understanding of financial content across both research-oriented and business-relevant contexts.
On industry-recognized benchmarks, Articul8’s A8-FinDSM consistently outperforms much larger general-purpose models. For example, on FinQA, which tests multi-step reasoning across financial documents, A8-FinDSM achieved 80.6% accuracy, compared to 75–77% for GPT-based OSS models. On TFNS, a benchmark that measures sentiment analysis on financial news, A8-FinDSM delivered higher precision and avoided the false positives that can distort trading decisions. These benchmark results reinforce the trends seen in our domain-specific evaluations. They demonstrate that A8-FinDSM is not only strong in practical, real-world tasks (like parsing disclosures and analyzing holdings), but also robust across academic tests of reasoning and financial natural language processing.
A8-FinDSM Thinks Like a Financial Analyst
With billions of dollars hinging on key financial metrics, surface-level summaries don’t cut it. Yet, when analyzing corporate results, most general-purpose AI models merely summarize obvious, surface-level facts while missing the deeper context, trends, and precision that tell a fuller story. As a result, general LLMs provide generic narratives, leaving the analyst hungry for actionable intelligence.
The A8-FinDSM transforms the equation. Purpose-built for financial analyses, it reasons like an analyst by grounding every insight with data from verified company filings, such as performance data and historical context.
The contrast appears when we tasked the A8-FinDSM and ChatGPT-4o models to write an executive summary of AutoZone’s financial results presentation and compared the results. While ChatGPT produced a readable generalized overview, the A8-FinDSM delivered a more powerful output: a data-driven report complete with verified figures, comparative metrics, and shareholder insights. The A8-FinDSM's expert-level reasoning transforms financial analysis from generic summaries into decision-critical insights. For analysts making high-stakes calls, hard metrics and data are not optional. With the A8-FinDSM, analysts gain a trusted partner that analyzes, not merely summarizes, the complex financial data to identify investment opportunities.

Built on the Language of Finance
While general-purpose models get trained on information from the public internet, the A8-FinDSM's performance advantage comes not just from the volume of its training data, but from deep immersion in finance-specific sources.
- 10-K annual reports and 10-Q quarterly filings
- Earnings call transcripts
- FINRA filings
- Investor day presentations
- Equity and credit research reports
- Financial analyst commentary
The A8-FinDSM ingested tens of millions of pages from these sources, effectively every SEC filing from the past two decades plus thousands of hours of calls. This immersion in financial language means A8-FinDSM does not just process, but truly "speaks finance" with precision and context that general models cannot match. Using this model means the analyst would be partnering with an expert who understands the difference between "adjusted EBITDA" and "GAAP net income," and senses the strategic shift in a CEO's phrasing from one quarter to the next, while contextualizing a company's R&D spend against its industry peers. With the help of the Table Understanding Agent, this information can be processed quickly so an analyst can readily identify key context to drive better decisions.
Redefining Financial AI
At Articul8, we turn data chaos into clarity. A8-FinDSM consistently outperforms much larger general models while running more efficiently, enabling financial institutions to reduce errors, surface insights, and make faster, more confident decisions. The Table Understanding Agent amplifies this impact by addressing a critical operational challenge in finance: the accurate and complete extraction of data from tables from complex documents. By delivering structured, reliable data in seconds, it minimizes human error, outperforms OCR and text-based extraction, expedites analysis, enhances compliance workflows, and ensures that downstream models consistently receive accurate, ready-to-use inputs. The Table Understanding Agent offers relief for analysts poring over reams of data and by allowing them to make key decisions faster and with confidence.
In a landscape where mistakes are costly and precision is everything, Articul8 delivers the only GenAI solution that truly speaks the language of finance and does so rapidly and at scale.
Together, the A8-FinDSM and the Table Understanding Agent form the first end-to-end financial GenAI stack that captures the data, understands the data, reasons over the data, and delivers decision-ready insights autonomously.