
The Expert Advantage: Domain-specific models outperform General Purpose Models
Articul8's Domain-specific Models Crush OpenAI's OSS Models Across Key Benchmarks
In the fast-paced world of generative AI, innovation never sleeps. Just yesterday, on August 5, 2025, OpenAI unveiled its latest open-weight models, GPT-OSS-120b and GPT-OSS-20b – groundbreaking releases designed to excel in advanced reasoning while being optimized for efficient deployment, even on laptops. These models represent a significant step forward in making high-performance AI more accessible, marking OpenAI's first open-weight large language models since GPT-2 in 2019. At Articul8, we applaud such advancements that push the boundaries of what's possible in general-purpose AI.
Yet, within 24 hours of this release, Articul8’s research team conducted a comprehensive benchmarking analysis of OpenAI’s new models against our suite of domain-specific generative AI models. The results clearly validated our focus on building specialized solutions for industry-specific applications. Across key benchmarks in finance, energy, aerospace, hardware design (Verilog), and Text-to-SQL tasks, our models consistently outperformed the latest open-weigh offerings. This swift evaluation highlights the depth and responsiveness of our research team – and reinforces that for complex, real-world cases, domain-specific models deliver superior performance.
To illustrate the superiority of Articul8's models, we've included detailed comparisons below on tests designed by domain experts. These highlight how our efficient domain-specific models deliver far better performance – often by double-digit margins, showcasing world-class efficiency and expertise.
Finance: Precision in Complex QA Tasks
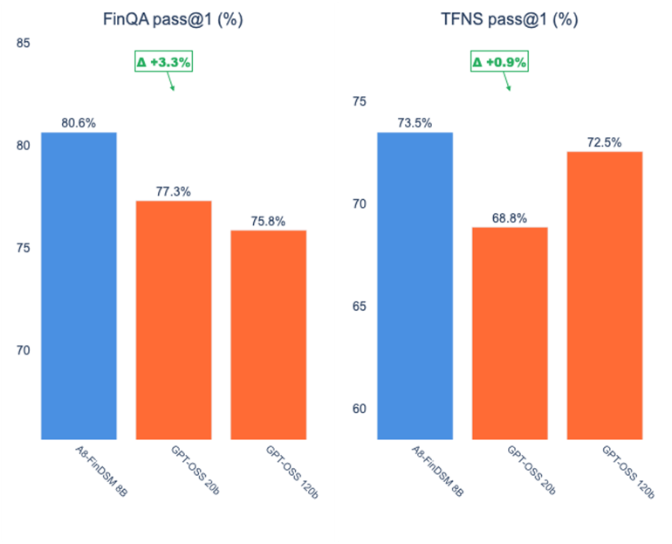
In financial question-answering benchmarks like FinQA and TFNS, our A8-FinDSM model achieved pass@1 scores of 80.63% and 73.47%, respectively. This edged out GPT-OSS-20b (77.29%, 68.84%) and surpassed gpt-oss-120b (75.85%, 72.53%). Despite being a fraction of the size, A8-FinDSM excels in tabular and conversational reasoning, delivering the kind of nuanced insights financial experts demand.
| Model | Parameter Size | FinQA pass@1 (%) | TFNS pass@1 (%) |
| A8-FinDSM | 8B | 80.63 | 73.47 |
| gpt-oss-20b | 20B | 77.29 | 68.84 |
| gpt-oss-120b | 120B | 75.85 | 72.53 |
Building Energy-specific Expert DSMs: Powering the Next-Generation Platform for Energy
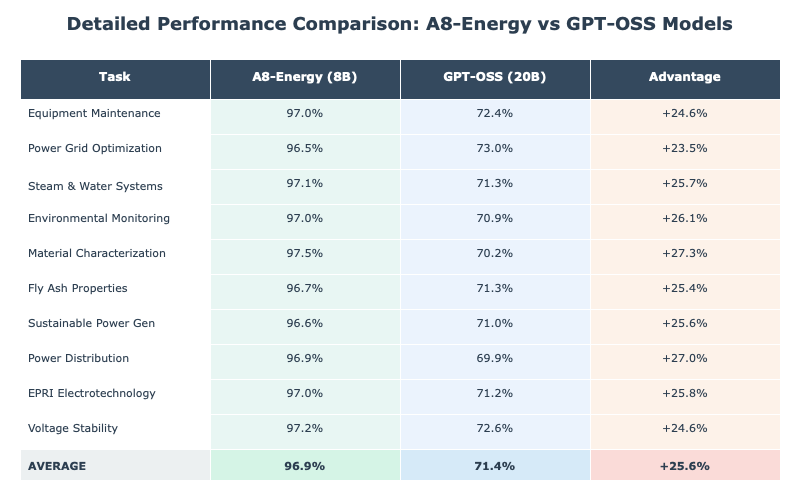
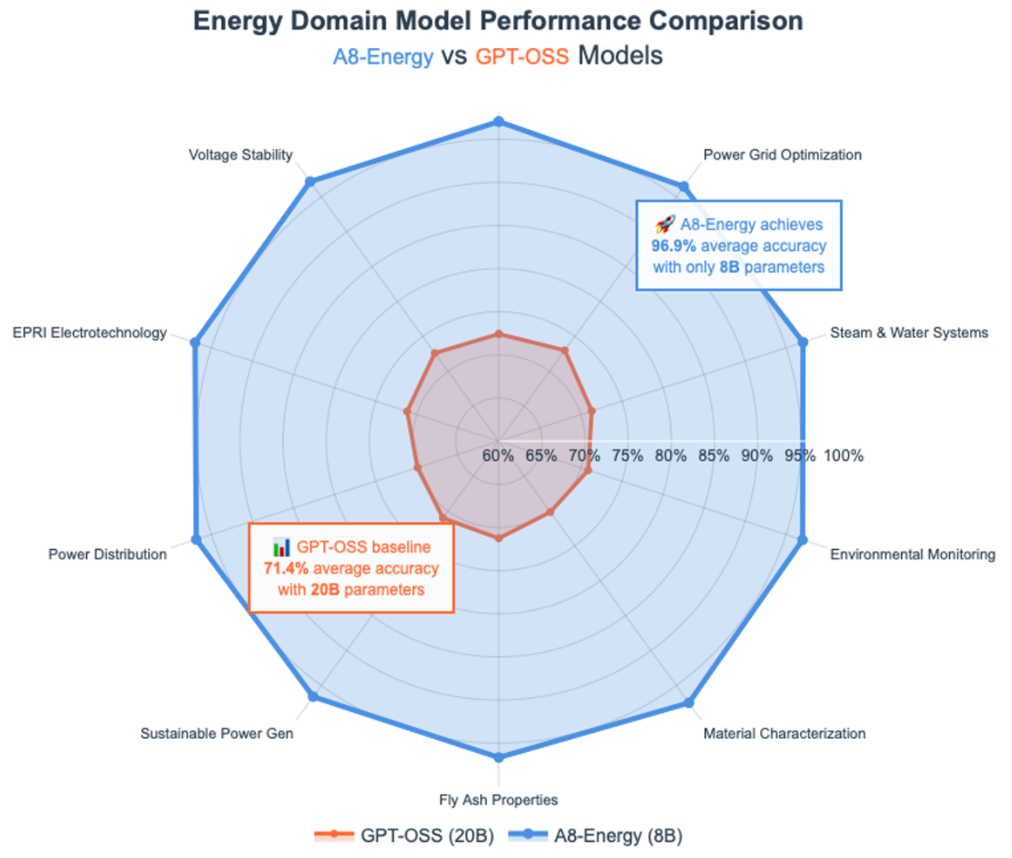
Building on our ongoing commitment to the energy sector, as explored in our recent blog post "Building Energy Domain-Specific GenAI Models That Reason Like Experts", our A8-Energy model continues to set the standard. Across 10 specialized topics, from equipment maintenance to voltage stability, our model averaged 96.9% accuracy, towering over GPT-OSS-20b's 71.3%. These results highlight how our models, trained on vast domain datasets from EPRI (Electric Power Research Institute), reason with the depth and precision of industry veterans, enabling breakthroughs in grid optimization and environmental monitoring.
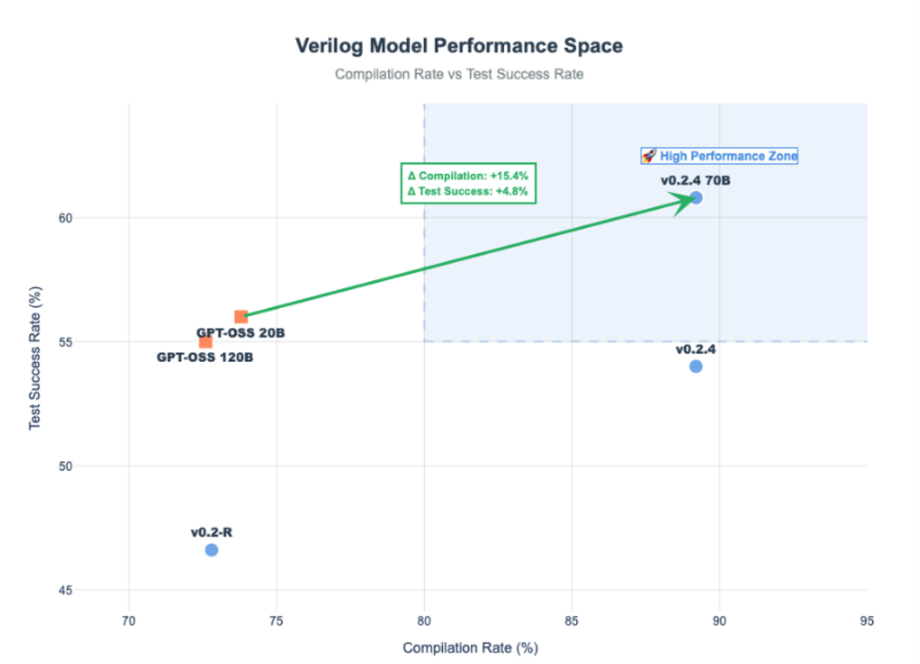
Verilog: Reliability in Hardware Design
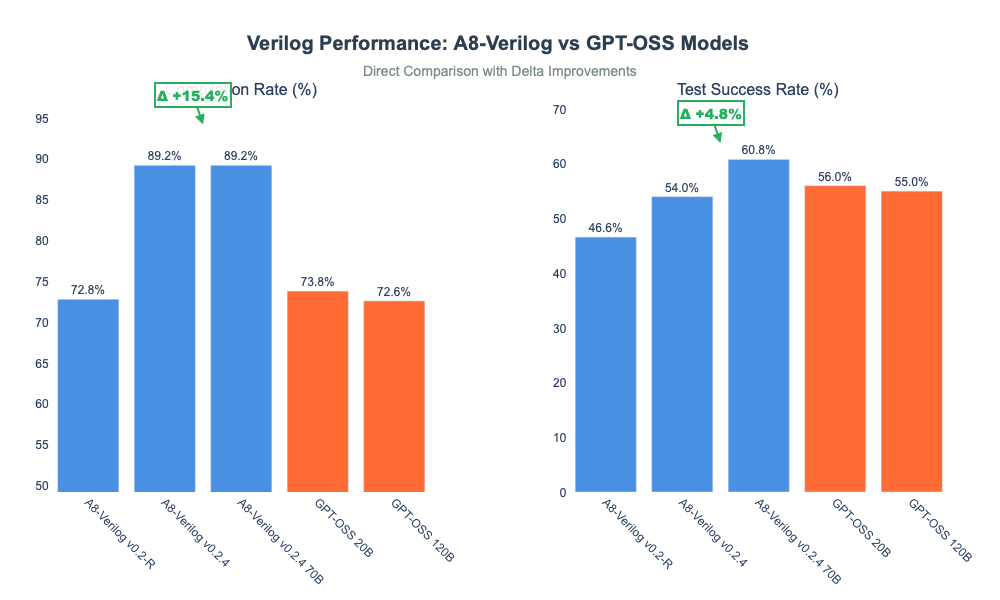
For hardware description language tasks, our A8-Verilog v0.2.4 (8B) model posted a compilation rate of 89.2% and test success rate of 54%, outperforming GPT-OSS-20b (73.8%, 56%) and GPT-OSS-120b (72.6%, 55%) in syntactic accuracy. Even our larger A8-Verilog v0.2.4 70B variant pushed test success to 60.8%, reinforcing the value of domain specialization in generating robust, compilable Verilog code.
| Model | Parameter Size | Compilation Rate (Avg) | Test Success Rate (Avg) |
| A8-Verilog v0.2.4 | 8B | 0.892 | 0.54 |
| A8-Verilog v0.2.4 70B | 70B | 0.892 | 0.608 |
| GPT-OSS-20B | 20B | 0.738 | 0.56 |
| GPT-OSS-120B | 120B | 0.726 | 0.55 |
Text-to-SQL: Practical Efficiency in Data Querying
In Text-to-SQL scenarios, our A8_Text2SQL variants not only maintained competitive latencies but also excelled in accuracy, with mean scores around 73% compared to OSS models' 61-62%. While GPT-OSS models on optimized hardware showed faster inference, A8's focus on precision makes it the superior choice for accurate, enterprise-grade SQL generation.
| Model / Variant | Parameter Size | Mean Accuracy (%) |
| A8_Text2SQL | ~8B | 73.18 |
| GPT-OSS-20B | 20B | 61.44 |
| GPT-OSS-120B | 120B | 62.29 |
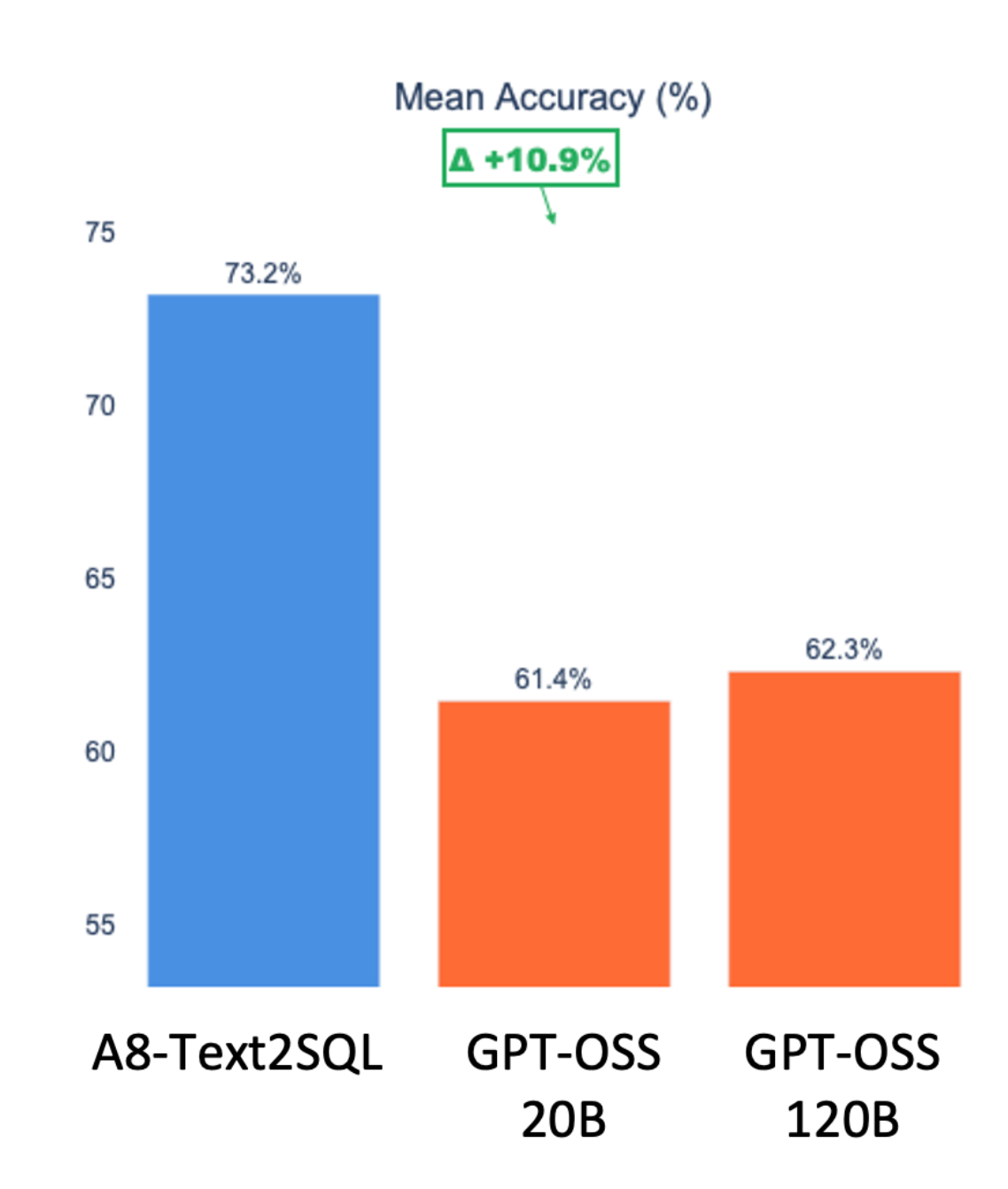
The accuracy plots reveal A8's clear lead in correctness, prioritizing quality over speed for mission-critical data tasks.
This swift benchmarking effort isn't just about numbers; it's a testament to Articul8's world-class research infrastructure. Our team leverages our A8 platform to train and fine-tune models and achieve the groundbreaking results. The inclusion of these models in our A8 platform or in our LLMIQTM Agent, available on the AWS Agent Marketplace mean that you can gain access to these performant and efficient models today.
To make these insights even more actionable, we've updated our LLMIQTM agent, now deployed seamlessly on AWS Agent Marketplace. As detailed in our blog "Smarter GenAI Agents Ready to Deploy", LLMIQTM dynamically evaluates and selects the optimal model for any given task in real-time. With the integration of these latest benchmarks against OpenAI's releases, LLMIQTM ensures users always harness the best-performing solution, whether it's our domain-specific models or complementary general models – driving efficiency and innovation at scale.
At Articul8, we believe the future of AI lies in harmony between broad capabilities and deep expertise. While general models like those from OpenAI and Meta democratize access, domain-specific models unlock transformative value in specialized fields. Our results speak volumes: in their respective realms, these tailored models aren't just competitive – they're unparalleled. We're excited to continue this journey, collaborating with the AI community to build a more intelligent, industry-ready world.
Stay tuned for more updates, and explore our models today at Articul8.ai.